NILAI PENYIMPANGAN DATA
Ukuran
Penyebaran/penyimpangan adalah suatu ukuran baik parameter atau statistika
untuk mengetahui seberapa besar penyimpangan data dengan nilai rata-rata
hitungnya. Ukuran ini kadang-kadang dinamakan pula ukuran variasi, yang menggambarkan
bagaimana berpencarnya data kuantitatif.
Untuk
mengukur tingkat penyimpangan dari suatu nilai variabel dapat digunakan dengan
tiga cara, yaitu ukuran jarak (range) yang merupakan selisih data terbesar
dengan data terkecil, simpangan rata-rata (deviasi rata-rata) dan simpangan
baku (deviasi standart).
RANGE
Jarak atau kisaran nilai (range) merupakan ukuran yang paling sederhana dari
ukuran penyebaran. Jarak merupakan perbedaan antara nilai terbesar dan terkecil
dalam suatu kelompok data baik data populasi atau sampel. Semakin kecil ukuran
jarak menunjukan karakter yang lebih baik, karena berarti data mendekati nilai
pusat dan kompak.
RANGE= NILAI
TERBESAR-NILAI TERKECIL
Contoh Range :
Berikut merupakan laju inflasi dari
Negara Indonesia, Malaysia, dan Thailand. Hitung range-nya!
TAHUN
|
Laju
Inflasi (%)
|
Indonesia
|
Thailand
|
Malaysia
|
2002
|
10
|
2
|
2
|
2003
|
5
|
2
|
1
|
2004
|
6
|
3
|
2
|
2005
|
17
|
6
|
4
|
2006
|
6
|
3
|
3
|
Penyelesaian :
Nilai
|
Indonesia
|
Thailand
|
Malaysia
|
Tertinggi
|
17
|
6
|
4
|
Terendah
|
5
|
2
|
1
|
Jarak
|
17-5=12
|
6-2=4
|
4-1=3
|
SIMPANGAN RATA-RATA (MEAN DEVIATION)
Deviasi rata-rata adalah rata-rata hitung dari nilai mutlak deviasi antara
nilai data pengamatan dnegan rata-rata hitungnya.
Bentuk rumus deviasi rata-rata ini biasa
disingkat dengan MD (mean deviation) atau AD (average deviation), rumus rumus
tersebut dapat kita lihat dibawah ini:
Untuk rumus sampel digunakan X sebagai pengganti µ sebagai
berikut
Contoh :
Dari contoh soal yang pertama kita dapat lanjutkan dengan berikut ini:
- Untuk mendapatkan nilai | xi – x |, kita bisa jumlahkan
nilai pengamatan dan di bagi dengan jumlah yang diteliti.
- Untuk soal yg diatas berarti: 39 / 6 = 6.5. Karena
contoh di atas menggunakan data sampel, sehingga rumus yang digunakan juga
menggunakan notasi sampel.
MD = 7 / 6 = 1.17.
VARIANS
Varians dan standar deviasi adalah sebuah ukuran
penyebaran yang menunjukan standar penyimpangan atau deviasi data terhadap
nilai rata-ratanya.
Varians adalah rata-rata hitung deviasi kuadrat
setiap data terhadap rata-rata hitungnya. Varians dapat dibedakan antara
varians populasi dan varians sampel. Varians populasi (σ dibaca tho) adalah
deviasi kuadrat dari setiap data terhadap rata-rata hitung semua data dalam
populasi. Varians sampel adalah deviasi kuadrat dari setiap data rata-rata
hitung terhadap semua data dalam sampel dimana sampel adalah bagian dari
populasi.
Varians memiliki kelemahan dimana nilai varians
dalam bentuk kuadrad, seperti tahun kuadrat dalam hal tertentu lebih suit
menginterpretasikannya dibandingkan dengan ukuran range yang merupakan selisih
nilai tertinggi dan nilai terendah atau deviasi rata-rata yang merupakan
rata-rata hitung selisih data dari rata-rata hitungnya. Oleh sebab itu, untuk
memperoleh satuian yang sama dengan satuan data awal, maka dilakukan dengan
mencari akar kuadrad dari varians populasi. Akar kuadrad dari varians populasi
disebut standar deviasi.
Standar
Deviasi
Standar deviasi disebut juga simpangan
baku. Seperti halnya varians, standar deviasi juga merupakan suatu ukuran dispersi
atau variasi. Standar deviasi merupakan ukuran dispersi yang paling
banyak dipakai. Hal ini mungkin karena standar deviasi mempunyai satuan
ukuran yang sama dengan satuan ukuran data asalnya. Misalnya, bila satuan
data asalnya adalah cm, maka satuan standar deviasinya juga cm.
Sebaliknya, varians memiliki satuan kuadrat dari data asalnya (misalnya cm2).
Simbol standar deviasi untuk populasi adalah σ (baca: sigma) dan untuk sampel
adalah s.
Standar Deviasi Untuk Populasi
Standar
Deviasi Untuk Sampel
Contoh data tunggal
Untuk mendapatkan nilai variansi dan standar deviasi dari contoh di atas
dapat kita lihat pada penjelasan berikut ini:
- Dari
contoh tersebut diatas sudah jelas dari mana kita mendapatkan (xi – x)2
tersebut.
- Variansi
yang akan kita pakai disini juga variansi sampel, karena data yang kita
gunakan adalalah data sampel. Dari rumus diatas sudah jelas bagai mana
kita dapat mendapatkan nilai tersebut.
- Jadi,
Variansi: Sampel (s2) = 9.5 / 5 = 1.9. Varian sampel yang kita dapat
yaitu: 1.9. dan Standar Deviasi (S) = √1.9 = 1.38.
Varians dan Standar Deviasi
data Kelompok
Rumus varians dan standar deviasi untuk data kelompok adalah sebagai berikut
Contoh dari Varians dan Standar Deviasi untuk data berkelompok
Berikut merupakan nilai statistik dari 50 mahasiswa.
Kegunaan deviasi rata-rata
dan deviasi standar
Baik deviasi rata-rata maupun deviasi standar keduanya berguna sebagai
ukuran untuk mengetahui variabilitas data dan untuk mengetahui homogenitas
data.


















{kind=link}
{kind=link}
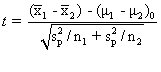{kind=link}
{kind=link}
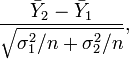{kind=link}